This is the second part of the Anatomy of RWA tokenization process.
I changed the previous presentation method in this article, separating threat modeling from the RWA tokenization process. Now, all the threat modeling-related content is presented using a block quote (with an orange bar on the left side) wherever necessary. This should provide a more fluent reading experience.
For those more interested in the RWA process instead of threat modeling, you can skip all the block quotes and finish reading in about 4 minutes.
Details of the RWA tokenization process - Part II
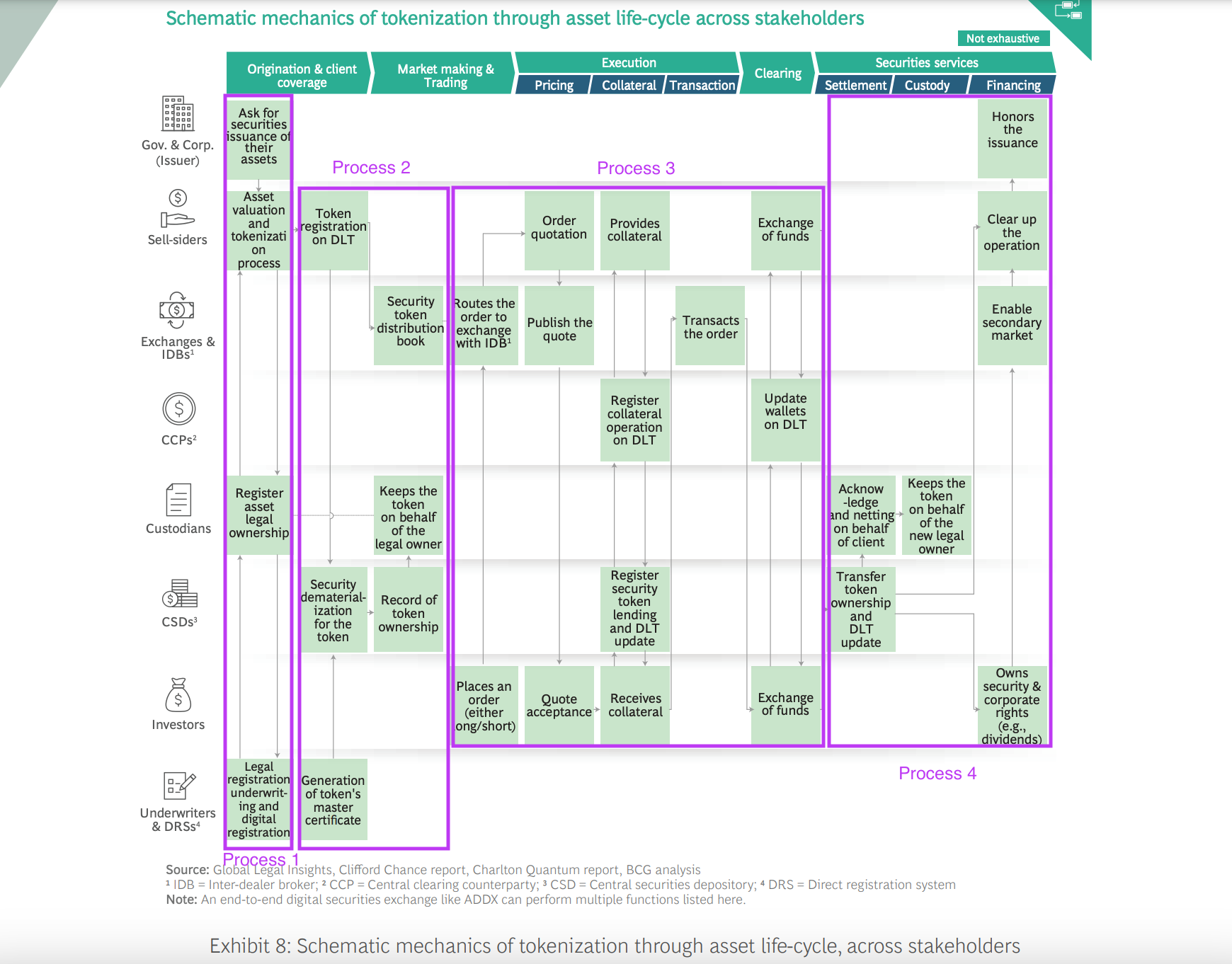
The above illustration comes from a report, “Relevance of on-chain asset tokenization in crypto winter,” from BCG. It was a brilliant report. I love this illustration because it can be used to model the threats to RWA. This post will focus on processes 3 and 4. The previous two processes are analyzed and explained in detail in the previous article.
Let’s dive right in.
Transaction Execution & Collateral Management
According to my definition of internal and external systems in the previous article, this process is considered internal.
As the analysis progressed, I realized that my previous definition of internal and external systems for threat modeling was centered around technical developers. What is internal to a tech team could be external to a legal team. The revised version will be proposed at the end of this article.
It may seem like a complex process at first glance. Still, many intermediaries, like the role of IDBs, quotation publishing and management, and order matching, can and should be replaced by blockchain. Let’s add a pure blockchain version of process 3, named transaction execution, to our existing system model:
Simple, right?
Well, not quite. It is a much simpler way to conceptualize than the traditional solution. Still, the underlying blockchain architecture involved in this transaction execution step is beyond simple.
This is the motivation that drove me to find a new way to model threats in blockchain. From a 10,000-foot view, everything looks easy peasy: Just execute the smart contract, and it's done. Another extreme is going down to the function or opcode level to model threats. It is undoubtedly more accurate but not scalable at all.
permission blockchain has very strict entry rules on who can participate, in contrast to a public one, where everybody with an Internet connection can participate.
To understand why a permissioned blockchain is used here, we must first understand the primary and secondary market concepts.
Primary market: Assets are traded directly between the asset issuer and the investor. It is usually illiquid compared to the secondary market but offers transaction compliance and privacy.
Secondary market: Assets are traded between investors using public exchanges like the NYSE and NASDAQ and decentralized exchanges (DEXs). This market has higher liquidity and provides effective price discovery but less privacy.
The 4 processes shown in the BCG report mainly depict a token setup procedure for the secondary market, meaning these processes happen inside a primary market. Thus, a permissioned blockchain is typically used to satisfy legal requirements.
However, the secondary market is usually set up on a public blockchain, so how can an asset on a permissioned blockchain be traded on a public blockchain?
And here comes the complexity. Some projects, like Centrifuge, issue assets on a permissioned blockchain and then create another program called Tinlake to bridge the asset to Ethereum, a public blockchain. Others, like Mantra, use the same infrastructure for primary issuance and secondary market trading through their own DEX.
Now we have multiple chains with completely different tech stacks and some middlewares to model. How is it possible to capture so much complexity under one threat modeling technique such as STRIDE?
Quick though:
Normally, threat modeling is done using multiple techniques, here we only focus on STRIDE as a start and gradually add more to construct a hybrid approach in the end.
Let’s use the S (Spoofing) in STRIDE model as an example. Spoofing means pretending to be something or someone other than yourself.
Current definition is designed as a catch-all, which means every technical setup can be covered. It’s like saying you need to do good things but what is "good" various with contexts. It maybe a good :) motto but a not a very applicable one. The moral here is that the hard part is to distinguish what’s good.
In the context of blockchain, the problem translates to "the thing/person initiates a transaction under a name must be the same thing/person as registered under the same name." Still too broad and not applicable, let’s narrow it down.
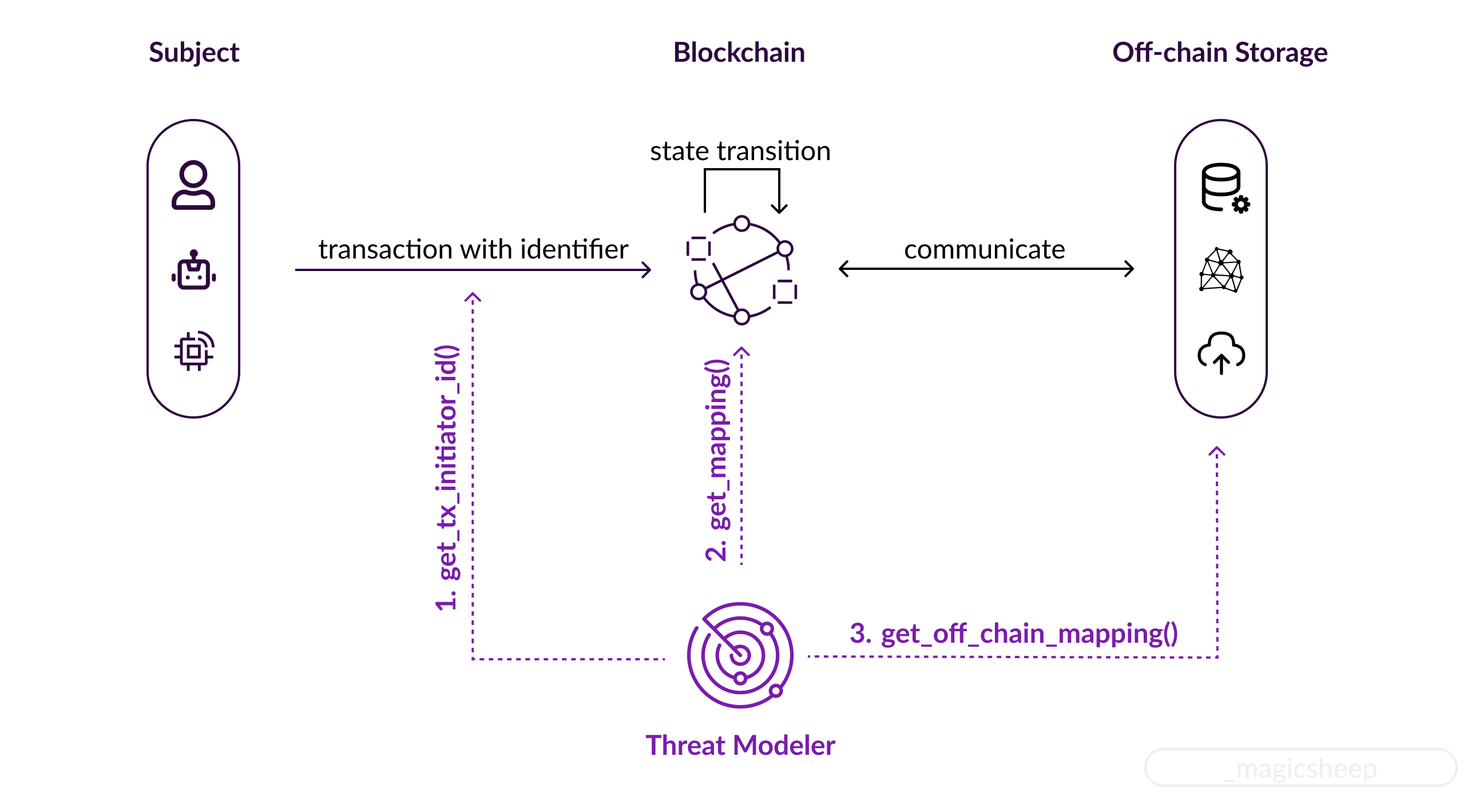
The above statement implies two things: 1) we can get the correct unique identifier of the subject who initiated a transaction, and 2) we have an immutable record that stores the correct mapping between a name and the unique identifier. For simplicity, the illustration below does not include the actual techniques used for communication between blockchain and off-chain storage such as oracles, data indexers and etc.
The desired result, or the blockchain-specific S (Spoofing) model, would be either:
1) get_tx_initiator_id() = get_mapping() for public blockchain, or
2) get_tx_initiator_id() = get_off_chain_mapping(get_mapping()) for permissioned blockchain.
Two things can get easily overlooked.
The first one is the transaction initiator’s identifier. Normally, we treat the sender’s public address as the initiator’s ID. The problem is that it ignores the possibility of a replay attack. Of course, we have nonces in a TX to mitigate such issues, but for threat modeling, we should not rely on such implementation details. We must instead not assume a valid TX is always sent from the account owner.
The second thing is the mapping. For a public blockchain, we usually treat the mapping as 1) a signature that proves the private key maps to a particular public key and 2) the fact a valid signature is produced proves that the sender maps to the public address derived from that public key.
However, this is not the case for blockchains that require a public address to be mapped to a unique, real-world entity. Blockchain is a state machine replication engine, not a database; when a large amount of data is involved, such as KYC data, an off-chain storage solution is often used. That means we need to map the public address further to an actual entity after we get the on-chain mapping. We need a function get_off_chain_mapping() to retrieve it from a decentralized storage network, a cloud backup, or an on-premise database.
Transaction Settlement
Finally! We arrive at the last process of the real-world asset tokenization setup. After this step, our precious token can be traded on a secondary market. Ka-ching!
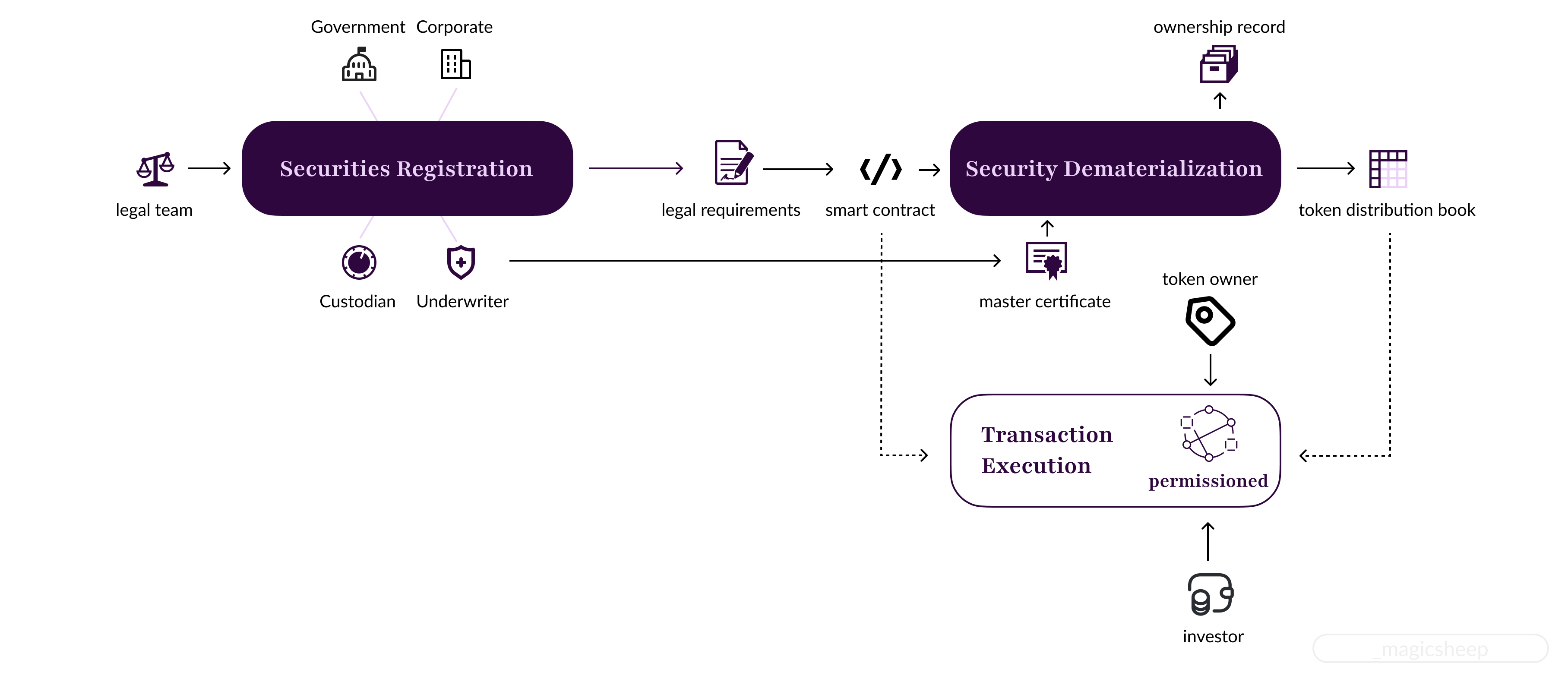
After the funds are transferred on the blockchain, the actual asset needs to be transferred, and this means two things: 1) the digital ownership record of the asset needs to change, and 2) the physical asset needs to be somehow transferred to the new owner.
If a custodian is used for the digital ownership record, this means that in addition to changing the on-chain record through a smart contract, a separate ledger held by the custodian also needs to change.
For the actual transfer of an asset, if a custodian is used, the delivery will be handled using pre-negotiated terms. If not, the delivery of the physical item should be handled by the RWA platform.
Traditionally, after the asset is transferred, some recognition from the asset issuer is also needed to certify the new owner’s legitimacy. It’s unnecessary in the blockchain solution because the chain holds the immutable token record; legitimacy is automatically proved by simply having the token.
Now, the new asset owner can choose to enable trading of these tokens on a secondary market or not. Some primary market companies also offer secondary market services, while others don’t. That means a second blockchain, often a public one, is often used for secondary market setup. This further complicates the overall RWA tokenization architecture, but let’s first add process 4 to our existing process diagram.
If an investor chooses to enable a secondary market with another blockchain, an intermediary process called bridging is required. It can be done in two ways: either through an escrow service provided by some companies or using a communication protocol like the XCMP (cross consensus messaging protocol) created by Polkadot.
These bridges are also a threat source. Notable hacks have occurred on bridges, causing the loss of hundreds of millions of dollars.
We can see that using bridges adds yet another layer of complexity to the RWA tokenization process. If we choose to do threat modeling on bridges themselves, it will be a one-model-one-implementation approach, defeating our endeavor to create a scalable threat modeling methodology.
However, I’m not saying bridges should never be modeled individually. If your team is building a bridge, then, of course, you need to model it. The important thing here is again how to determine what is an internal and external system.
As promised, I present my proposed method for dividing a system under modeling into internal and external systems.
List the core business goals.
A product should serve its customers, so everything directly related to the core business goals should considered internal systems. For example, if a team is building a decentralized exchange (DEX) that only handles token swaps. The most crucial function that will render the product useless should it fail is the smart contract that carries out the actual swapping of tokens. Other components, such as price oracles, liquidity bridges, etc., are all add-on features to make the product robust. Thus, the swap contract should be considered an internal system, and all other parts are considered external systems.
Treat the internal system as whiteboxes & External system as blackboxes.
We need to treat every input source to our internal system as hostile. Let's continue the DEX example. Suppose the swap contract is connected to a pricing oracle. First, we need to build a data flow diagram (DFD) for the contract. In current research, known as "taint analysis," the next step is usually to mark all the places touched by the price data as tainted.
The first problem is that we could mark all the contracts as tainted since their sole goal is to perform price-informed swaps.
Another problem is the definition of "malicious" or "tainted." In traditional security settings, malicious or malformed data is easily recognizable, but what price should be considered malicious? Prices fluctuate constantly, and blockchains have latencies. Hence, the price pulled in through an oracle is likely different from when executing the transaction.
I’m still trying to figure out how to limit the taint propagation in a scalable way. However, for the second problem, we can define a mechanism called threat oracle. It is a concept widely used in fuzzers to determine what should be considered an attack. In the spirit of making it scalable to different blockchain project implementations and use cases, it should expose the following interfaces for customization:
set_target(): Set which variable to track.
set_threshold(): Set the customized function that will return a boolean value indicating whether the tracked target is considered an attack.
However, it is usually impossible to tell the security threshold; many researchers choose a number randomly or based on empirical analysis. Randomly pulling out a number is obviously not a good solution, but empirical analysis also has flaws. It is challenging to find enough data on another system that has the exact functionality of the system under modeling. Simply put, what is empirical for others can not directly apply to a new system. The security threshold must come from direct data of the system under modeling.
Fuzzing is an excellent example to draw inspiration. But instead of randomly generating things as inputs to the set_threshold() function, we need a bounded input generation algorithm. The goal is not to just crash the system but to find out the boundaries that will render the outputs of a system undesirable after they are exceeded. What is considered desirable should be defined in the core business goals. That means our threat oracle should expose another interface: c. find_threshold(): Take business goals as input. The output is a function that can be used by the set_threshold() function.
The inputs to our set_threshold() function can also be type checks. For example, if your system utilizes some API to pull numbers from the off-chain world, the result of such an API call should only return numbers; otherwise, it should be considered an attack. That means when we call the set_target() function, we should also indicate the desired types of the target.
What’s next?
That's it, folks. We've completed understanding the whole RWA tokenization process conceptually. In the following article, I'll choose a real-world open-source project operating in the RWA field and apply a modified STRIDE modeling to see if it can actually find vulnerabilities.
If you like what you read, feel free to click on the subscribe button below ;) It's completely free.